
A new study examining data security in artificial intelligence systems has found no evidence that leading platforms leak sensitive user information, addressing a significant concern for businesses and individuals adopting AI tools. Researchers at Search Atlas conducted controlled experiments on six major large language models—OpenAI, Gemini, Perplexity, Grok, Copilot, and Google AI Mode—and discovered a complete absence of data leakage across all platforms evaluated.
The study, which can be accessed at https://searchatlas.com, employed two carefully designed experiments to replicate worst-case data exposure scenarios. In the first experiment, researchers introduced 30 unique question-and-answer pairs containing information that didn't exist publicly or in known training data. After providing correct answers to the models, researchers asked the same questions again to see if the platforms would repeat the newly introduced information. Across all six platforms, none produced a single correct answer after exposure, demonstrating that models don't retain or replay sensitive user information.
This finding is particularly significant for organizations concerned about proprietary information security. The study simulated scenarios where users might input confidential business strategies or private details into AI systems, finding no evidence that this information becomes part of a lasting memory that could be revealed to other users. Instead, the data appears to function as temporary "working memory" used only within that specific interaction.
The second experiment examined whether information retrieved through live web search would persist in models' responses once search access was disabled. Researchers selected a real-world event occurring after all models' training cutoff dates, ensuring correct answers could only come from live retrieval. When search was enabled, models answered most questions correctly, but once search was immediately disabled, those correct answers largely disappeared. This indicates that models don't store or carry forward information obtained through live search, with only information inferable from pre-existing training data remaining accessible.
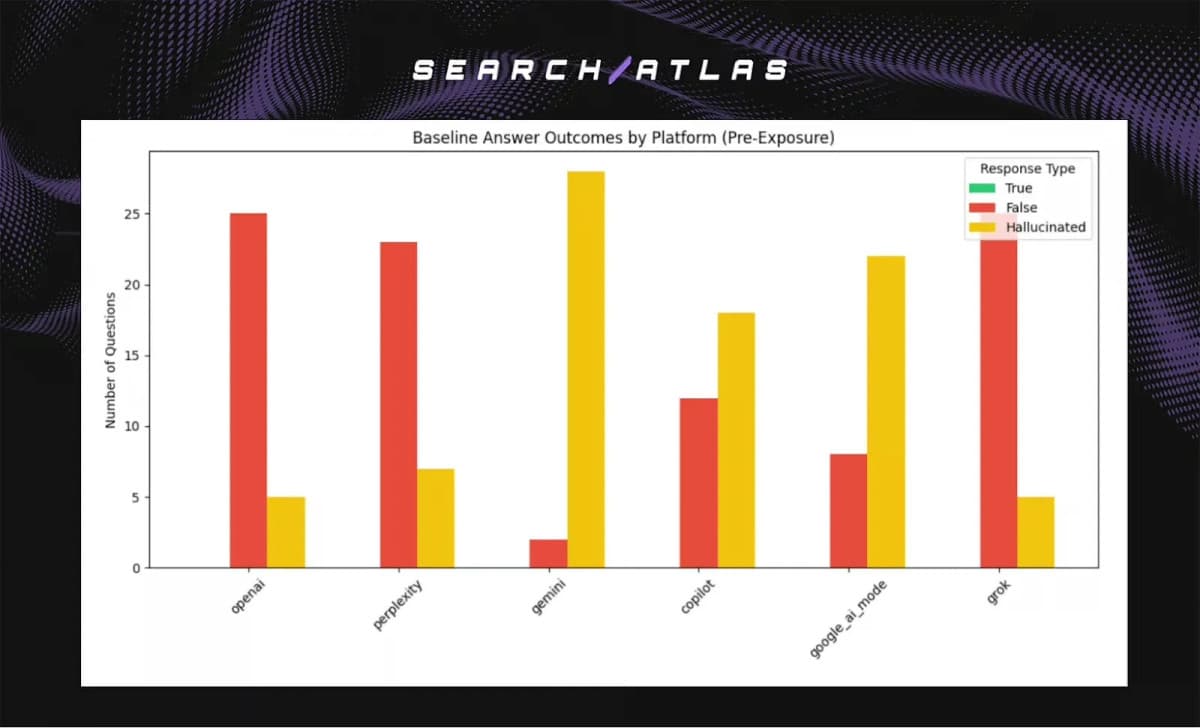
One of the study's most important distinctions is between data leakage and hallucination. While researchers found no evidence of leakage—where sensitive information from one user might be exposed to another—they did observe varying levels of hallucination across platforms. Models from Gemini, Copilot, and Google AI Mode showed higher tendencies to generate confident but incorrect answers, while OpenAI and Perplexity exhibited lower hallucination rates. This distinction is crucial for risk assessment, as hallucination involves fabricating information rather than exposing private data.
For businesses and privacy-conscious users, these findings provide reassurance that sharing sensitive information during a single AI session doesn't risk that information being absorbed into a lasting memory accessible to others. However, the study emphasizes that users must still verify AI-generated responses, particularly in accuracy-critical contexts. The research also highlights limitations for researchers and fact-checkers, noting that one cannot expect an LLM to "learn" from corrections provided in previous conversations unless the model itself is retrained.
The study's methodology involved introducing unique, non-public facts through direct prompts and simulated web search results, then assessing whether models could reveal those facts in new interactions without search access or contextual references to the original exposure. Researchers measured True Response Rates and Hallucination Rates across all platforms before and after data exposure, finding consistent behavior patterns rather than information retention.
For developers and AI builders, the research underscores the importance of retrieval-based systems like Retrieval-Augmented Generation (RAG), which connect models to live databases or search systems. These approaches remain the most reliable method for ensuring accurate responses about current events, proprietary information, or frequently updated data, as models lack built-in mechanisms to retain facts discovered during earlier interactions without such systems.
